
New ideas for making optimal use of experts in grant-funding
How to solicit expert opinions without stifling creativity

The importance of grant-funding panels in science cannot be overstated. Every year in the US, tens of billions of dollars of scientific grant-funding get allocated based on the whims of these panels. The opinions of panels have a massive influence over what can and cannot get researched.
Panels are often criticized by the progress studies community for the belief that they’re structured to incentivize risk-averse, derivative research. And the community has a point. A large group of domain experts having to almost unanimously approve an idea puts truly novel ideas at a disadvantage.
But, with all these new science funding organizations seemingly springing up out of the ground, they are now in the position of needing to find ways to responsibly allocate billions of dollars in capital. And, while the mantra of “fund people, not projects” is effective and goes a long way to reduce risk aversion, it is not the right formula in all cases. Many organizations are turning to the classics, panels and expert reviews.
In looking to build the future of innovation, these orgs have decided to employ the use of experts—as they should. The question is: how can they solicit expert opinions without stifling innovation and creativity?
In this piece, I’ll dive into some of the problems present with how panels are currently used and outline several strategies to overcome these issues. And, obviously, strategizing to overcome old issues always has the possibility of creating new problems. But that's life sometimes. At least these new-age grant funders who modify the 'industry standard' won’t be guilty of being boring and making the same-old science funding mistakes.
The current use of panel scores pretends they are more precise than they are
Humans are not always the best at making fine-grained predictions. Just because our general predictions about something are quite accurate does not make zooming in on those predictions a great idea. And this seems to be the case with panelists’ average scores of grants.
A 2015 paper by Danielle Li and Leila Agha looked at 130,000 NIH R1 grants to see how the grant scores from panelists correlated with the actual citations papers received. The results, which were likely what the authors expected, showed that awarded grants with higher panel scores generated more publications, more citations, more high-impact papers, and more patents on average. This paper affirmatively answered the question, “On average, do panelist scores tend to be highly correlated with the final citation count of a paper?”
However, there was another way to frame the question that the authors did not explore. And that alternative framing is, “How predictive are panel scores right around the cutoff point at which funding decisions are usually made?”
A follow-on analysis, using Li and Agha's dataset, done by Fang, Bowen, and Casadevall explored this exact question and demonstrated that the true story may be more complicated than the Li and Agha paper made it out to be. The authors found that within the top fifth of scores for awarded grants, panelist scores were a weak signal of performance at best. Within this bucket of awarded grants whose panel scores fell in the top quintile, a score in the top two percentile buckets proved to be a very reliable indicator of high performance. However, as the figures below show, the final performance of grants with percentiles between three and twenty were statistically indistinguishable from one another.
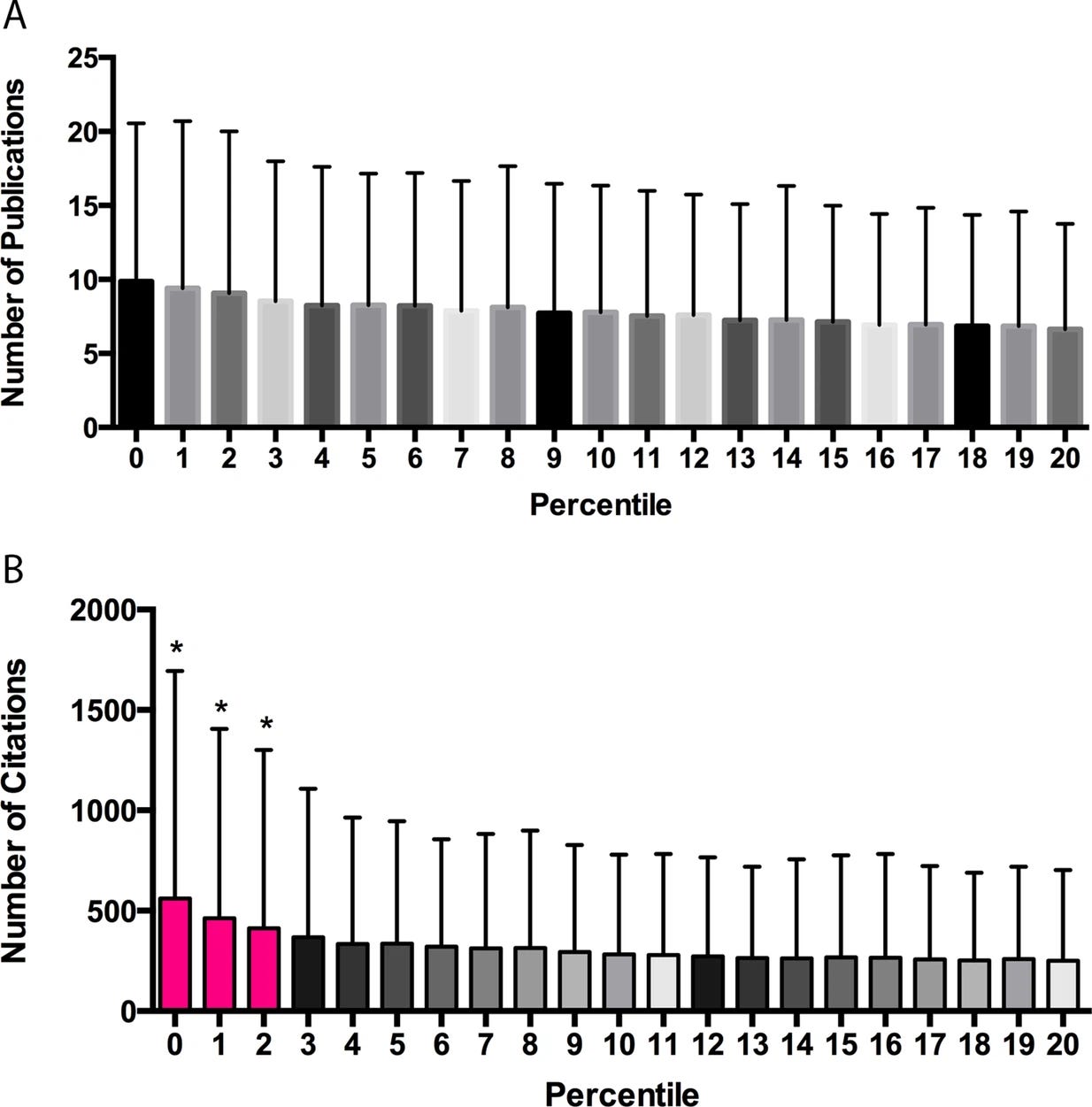
A panelist not being able to distinguish between a 15th percentile grant and a 6th percentile grant is a big deal because in many grant pools, including those of the NIH, the grant cutoff often falls somewhere around the tenth percentile.
The grant funding community needs to come up with better ways to decide between proposals that are decidedly in the top tier, but not exactly in the top 2%. In this current equilibrium, whether or not most of these top-tier applicants get funded seems to be determined more by randomness and bias from the reviewers than actual merit.
I’ll detail several ideas on how to overcome this issue in the final section. For now, the takeaway from this should not be that the panelists don’t know anything. Quite the opposite, they seem to be doing quite well on average. However, just because the panel scores seem to be doing a serviceable job of getting panels down to a shortlist of candidates, does not mean those same scores should be used in making the final selection.
Now, let’s look at the tradeoffs associated with panelists having high familiarity with a given application’s research area.
Expertise has its tradeoffs
Experts tend to find top proposals in their area (but at a cost)
Panelists who know more about an area have an advantage in separating top projects out from the rest of the pack in their area of expertise, but they also may bring some personal bias into the equation. Danielle Li, who you know from above, conducted a study analyzing the outcomes of NIH grant applicants who had panels made up of panelists whose research was closely related to theirs.
Her findings tell a very mixed story about the behavior of NIH panels with panelists whose research is related to an applicant’s. The positive finding is that panelists proved to be highly effective at accurately rating applications in their area that did, in fact, go on to receive high numbers of citations. For these eventual successes, having just one additional related reviewer on the panel, which can often number 30 or more panelists, corresponded to an applicant receiving an average score that was over 5% higher on average. To put that number in context, an unrelated application’s true quality, as measured in eventual citations, would have to be about two-thirds of a standard deviation higher (~34 citations) to receive that kind of a bump in score.
On its own, that’s not a major problem. There’s nothing wrong with being more sensitive to changes in quality in your own area of expertise than in others. That’s sort of how expertise works. However, the issue is that while reviewers were very likely to notice high-quality applications in their own areas, they were not equally likely to penalize poor applications in those same areas.
For poor applicants in an expert’s area, there was a slight negative effect on scores. But this marginal downside did little to offset the extreme bias towards noticing and scoring the best applications in an expert’s own area very highly. Having an additional panelist related to your area of research turned out to be the equivalent of applying with an application that was 14 citations better than it actually was.1
This finding is not some statistical fluke. Li even indicated that panelists told her as much. “Many of the reviewers I spoke with reported being more enthusiastic about proposals in their own area; several went further to say that one of the main benefits of serving as a reviewer is having the opportunity to advocate for more resources for one’s area of research.”
With expertise comes insight as well as bias. It's necessary to structure the use of experts to take advantage of that principle rather than get blindsided by it.
Experts don’t love novelty
Even though researchers tend to spot quality in their area of expertise, they don’t always love novelty. And this is reflected in the literature. Boudreau et. al conducted a fantastic study where they observed senior researchers’ ratings of the early-stage research proposals of junior faculty within their research institute. They generated the following graph showing how novelty affected the average scores of the applications.

The proposals began to take a massive hit in their average scores once they got into the top 20% of novelty. And you might be thinking, “maybe that’s not so bad because the top fifth might be made up of the truly wacky proposals.”
But, based on the findings from Uzzi et. al, that is most likely not the case. Uzzi et. al’s findings hint at the reality that this top quintile of novelty is where much of the truly ground-breaking research lies. They show that the probability of a hit paper, defined as being in the top 5% of its field in citations, comes somewhere in between the 85th percentile and 95th percentile of novelty. The top 5%...that might be where the wacky stuff is. Their definition of novelty is not exactly the same as Boudreau used, but it’s similar enough to indicate that the expert bias against novelty is quite costly.
As an additional sanity check, work by Wang et. al shows that novel research, while being far more likely to end up as a highly cited paper, is often relegated to less desirable journals despite its “hit” potential. This reflects an inherent bias against novelty by reviewers within a given research area despite the research’s substantial upside.
Novelty and Likelihood of being a top-cited paper
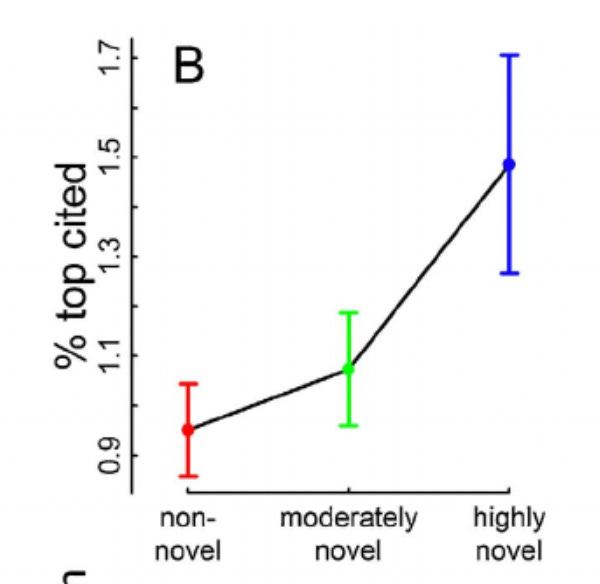
While the experts may be effective at locating top-tier, standard papers in their field. They don’t seem to exhibit high-level abilities at picking out novel research that may turn out to be a hit.
Making Optimal Use of Experts
So, we’ve established that:
Panels can be effective at ranking a top-tier of applications, but leave a lot to be desired when it comes to differentiating projects within that tier.
The top 2% of average scores from expert panelists did tend to be quite good, even if the 3rd through 20th percentiles were noisy.
Experts behave differently when scoring proposals in their own area of research than they do when scoring other areas in which they are less expert.
Panelists tend to punish most novel research proposals in an area, despite their high potential.
There are many ways to take advantage of the positives of experts while minimizing the impact of their defects. One set of strategies for a more ideal system of using experts might be:
When deciding which less-novel projects to fund
Use experts to separate a top-tier of about 20% of ideas from the rest of the ideas in their area of expertise.
Within that top-tier of ~ 20% of ideas, it might also be worth having the experts separate the top ~2% from the next 18%.
Funding that top ~2% may be a no-brainer in many cases. But for the next 18%, it may be worth making final cuts based on some other metric rather than their average rating.
For example, it might be worth it to fund the projects from most cheap to most expensive.
An org could also estimate the ROI in terms of social good for each project—assuming it achieves positive results—and fund the projects based on the rank-ordering of this ROI.
There are countless other options. Orgs should feel free to make this decision based on some metric that makes sense with their mission rather than strictly abiding by the rank-ordering of panelist scores. Within the top tier, those scores should be taken with many grains of salt.2
How to best handle the novel projects is not quite as clear-cut because there is less empirical data on organizations that focus on this. But I’d say that some good rules of thumb are:
Strategies for not letting novel projects fall through the cracks
Don't put too much faith in the experts’ average scores of novel projects.
Don’t incentivize the near-unanimous approval of ideas. Unanimous approval can be great, but many great ideas will have detractors. The perceived success of the ARPA-E program may in part be because, in selecting projects to fund, high-variance in review scores tends to be rewarded rather than punished.
Rewarding high variance in scores from experts may be an effective strategy. Since novel projects are inherently high variance, having just one subject-area expert who finds the novel idea exciting should be a positive sign. This is not dissimilar to many VCs having a “Champion Model” when it comes to early-stage funding, where if one partner is willing to champion an investment, the firm will make it.
Finally, reward proposals that have as, Uzzi et. al put it, “an injection of novelty into an otherwise exceptionally familiar mass of prior work.” Their work showed that research that was entirely novel throughout was no more likely to be highly cited than research with almost no novelty. It was the research that added in a piece of extreme novelty into an otherwise standard combination of ideas that was almost 60% more likely to become a hit paper than a standard paper.
Building on what is standard with a few key, novel insights is where you tend to find major breakthroughs. This entire list of recommendations is similar in spirit to what Uzzi et. al recommend. These recommendations largely take the standard structure of grant-funding panels and add in/substitute pieces of novelty into that formula rather than attempting to reinvent the process from the ground up.
Building something completely new can be great, but in many cases, the existing ‘best practices’ are onto something, they just need an injection of novelty to reach a new level of usefulness.
If anyone at one of these grant funding agencies would like to chat about this piece or about how they can do something truly new with the grant selection process, I’d love to talk. I hope you enjoyed the piece. Please subscribe or share with a friend if you liked it. It helps a lot:)
There was a related study done by Boudreau et. al within a given institute that also found that those who were experts in an area were more discerning at picking up on the highest quality proposals than non-experts. In contrast to the Li study, the authors also found that, on average, authors tended to be more strict in scoring their own areas of expertise. However, this study was done on a smaller, more specific sample of research proposals and researchers than the Li study, so the comparison is not exactly apples to apples. But, on the bright side, it did seem to confirm the hypothesis that experts are quite good at spotting high-quality proposals in comparison to non-experts.
And it should also be remembered that experts do not score projects in their own area of expertise the same as those outside of their area of expertise. So, in this context, apples-to-apples score comparisons can be a big mistake.