
Everything Old is New Again: Old research models for new-era semiconductor research
Alternative Title — How to optimally build at the top: the case for BBN-model orgs

Bottom Line Up Front: Recently, large pots of federal funds have been set aside for chip research. A significant portion of these funds should find their way to research teams that operate like the best research groups from the prior, vertically-integrated era. Two ideal teams to learn from are BBN — the prime ARPAnet contractor — and CMU’s early autonomous vehicle teams, who laid much of the groundwork for the autonomous vehicle revolution. Both groups were ideally structured to solve ambitious, vertically-integrated computing problems with small teams of people with broad technical knowledge. Each org was aggressively novelty-seeking, solved practical problems for real users, and was managed in a firm-like fashion. Groups with this older operating model possess key comparative advantages that make them superior to academic labs and VC-funded firms in many applied research areas. This includes somewhat speculative projects in the early proof-of-concept stage, a key focus area for the NSTC.
Introduction
Many experts believe we are living in a post-Moore’s law world. NVIDIA’s Jensen Huang and computing legends like John Hennessy and David Patterson count themselves among them. But that does not mean these predictions spell doom for the computing field. Their predictions simply acknowledge that we are approaching the end of the “there’s plenty of room at the bottom” era of general-purpose computing — and moving on to another.
As Hennessy and Patterson point out, this shift hearkens the semiconductor ecosystem back to a style of work that was common before the 1980s — an era FreakTakes has covered extensively. In this piece, I’ll detail how the best teams from that period operated and why it’s necessary to bring those operating models back to thrive in this new era of semiconductor design.
The piece is broken up into three sections.
In the first section, I briefly cover the history of the “there’s plenty of room at the bottom” era.
In the next section, I explain what experts believe a “there’s plenty of room at the top” era could look like. Current researchers and veterans like Hennessy, Patterson, and Leiserson et al. believe the shift to looking for progress at the top of the computing stack will involve the vertical integration of research teams and a focus on domain-specialized hardware.
In many ways, this is a shift back to how computing research groups used to operate before the 1980s. So, in the third section, I will summarize key management decisions that characterized some of the best old school computing organizations — such as BBN and the CMU autonomous vehicle groups.
With that, let’s get into it.

{kind=link}
This piece heavily draws on two prior FreakTakes pieces on the BBN and CMU teams:
“The Third University of Cambridge”: BBN and the Development of the ARPAnet
An Interview with Chuck Thorpe on CMU: Operating an autonomous vehicle research powerhouse
Readers familiar with the basics of semiconductor history may skip the first section. Readers familiar with Leiserson et al.’s “There’s plenty of room at the Top” paper may skip all but the final three paragraphs of the second section.
There was plenty of room at the bottom
The optimism that drove the early Moore’s Law era of general-purpose computing is well-characterized by Richard Feynman’s “There’s Plenty of Room at the Bottom,” speech to the American Physical Society in 1959. In his speech, Feynman implored scientists and engineers to focus their efforts on the exciting opportunity of engineering biological, electrical, and physical systems on exceedingly small scales. He believed we were nowhere near the limitations of physics when it came to engineering systems on these scales. So, he asserted that the area was ripe for talented engineers and scientists to pile in and build a world of systems whose possibilities were orders of magnitude beyond the status quo in 1959.
For decades, the semiconductor field did just that, doubling performance every 18-24 months until the early 2000s. It still continues to excel at a remarkable rate, simply with more tradeoffs than we have become accustomed to seeing. The practical foresight of individuals like Gordon Moore in his 1965 Moore’s Law paper, Robert Dennard et al. in the more technically-detailed 1974 Dennard Scaling paper, and Gordon Moore again in his 1975 paper — summarizing of the field’s progress and providing updated predictions for the coming decades — largely held true until the early 2000s.
As the early 2000s approached, it was becoming clear to many in the industry that the general approaches outlined in the Dennard Scaling paper were not going to continue to provide the same improvements. The aptly named 1999 Paul Packan paper, Pushing the Limits, outlined several physical limits the field was approaching with the current approaches — including thermal limit challenges. Many of the specific challenges Packan outlined in the paper had no known path of attack that did not entail major trade-offs. Industry attempted to take alternative paths of attack to continue to scale computing power — such as the increased emphasis on multi-core processors — but the limitations researchers like Packan outlined have proven to be quite difficult. Since the mid-2000s progress in the field has continued, but it has not been Moore’s Law-level progress.
So, if there is not much cost-efficient room to be found at the bottom, where should the field look? Well, many researchers believe the natural place to look is: the top.
There’s plenty of room at the top, but…
In Leiserson et al.’s 2020 paper, There’s plenty of room at the Top, a group of researchers from MIT outlines a vision for the potential gains in computing power by focusing on the top of the computing stack — software, algorithms, and hardware architecture. They are quick to point out that this approach will require divorcing one's thinking from the “rising tide lifts all boats” approach which many became accustomed to under Moore’s Law. The authors write:
Unlike the historical gains at the Bottom…gains at the Top will be opportunistic, uneven, and sporadic…they will be subject to diminishing returns as specific computations become better explored.
The authors paint a broad picture of what this integrated approach will look like, writing:
Architectures are likely to become increasingly heterogeneous, incorporating both general-purpose and special-purpose circuitry. To improve performance, programs will need to expose more parallelism and locality for the hardware to exploit. In addition, software performance engineers will need to collaborate with hardware architects so that new processors present simple and compelling abstractions that make it as easy as possible to exploit the hardware.
The authors then go on to demonstrate a toy example in the area of software performance engineering. They use a simple baseline problem as an example, multiplying two 4096-by-4096 matrices. To start, they implement this in the Python code that minimizes programmer time spent. They then proceed to do performance engineering until the same function eventually runs 60,000 times faster — first by changing to more efficient coding languages, then introducing parallelization, and beyond.

At the end of the performance engineering section, they reflect on what it will take for teams of researchers and engineers to effectively take advantage of opportunities analogous to this one in the future:
Because of the accumulated bloat created by years of reductionist design during the Moore era, there are great opportunities to make programs run faster. Unfortunately, directly solving [some arbitrary, domain-specific] problem A using specialized software requires expertise both in the domain of A and in performance engineering, which makes the process more costly and risky than simply using reductions. The resulting specialized software to solve A is often more complex than the software that reduces A to B. For example, the fully optimized code in Table 1 (version 7) is more than 20 times longer than the source code for the original Python version (version 1).
The authors’s next section explores a few major successes in the history of algorithmically-driven computing performance. They use the history of algorithms for matrix multiplication as a key example to note that while the history of algorithm improvements has been a bit uneven in terms of rate of discovery, in certain cases it has rivaled Moore’s Law-level progress.

The authors highlight algorithms as another area that, while only semi-reliable, holds extreme promise for continuing to push computing progress forward. Among other reasons, they think there might be promise in this approach because many commonly used algorithms were originally designed to utilize random access memory on the serial/sequential processors of the early 1960s and 1970s.1 They believe many algorithms that take this approach use modern hardware inefficiently because they under-utilize the parallel cores and vector units in modern machines.
But, at the end of the algorithms section, the authors once again note that there is a clear difficulty in pursuing problems of this form in the modern, rather modularized research ecosystem. They write:
These approaches actually make algorithm design harder, because the designer cannot easily understand the ramifications of a design choice. In the post-Moore era, it will be essential for algorithm designers and hardware architects to work together to find simple abstractions that designers can understand and that architects can implement efficiently.
In the final section, on hardware, the authors outline the general characteristics of computing areas which they believe can continue to experience extreme performance improvements — and which will curtail. Areas that benefit from parallelism and streamlining are notable examples with a lot of potential for progress to continue. The authors use the following graphic to highlight the continued progress in SPECint rate performance — a processing performance metric which increasingly benefits from parallelism as more cores are used — as an archetypal example of a metric that they expect to continue improving at a high rate.
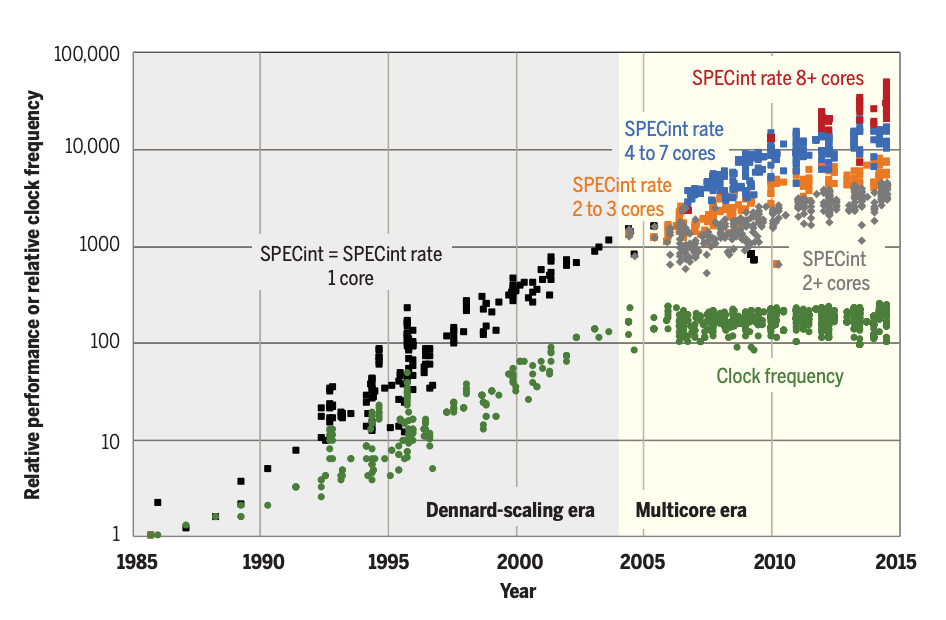
As designers increasingly embrace parallelism, Leiserson et al. believe “the main question will be how to streamline processors to exploit application parallelism.” In tackling this challenge, they expect two strategies to dominate. The first is that they expect designers to increasingly use simpler cores that require fewer transistors in chip designs. These simpler cores will be specifically chosen to efficiently accomplish the task at hand. For this to be worthwhile, designers must find ways to ensure two simplified cores incorporated in a specialized design can accomplish more than a single complex core.
On the second approach to tackling the challenge of streamlining processors, the authors write:
Domain specialization may be even more important than simplification. Hardware that is customized for an application domain can be much more streamlined and use many fewer transistors, enabling applications to run tens to hundreds of times faster. Perhaps the best example today is the graphics-processing unit (GPU), which contains many parallel “lanes” with streamlined processors specialized to computer graphics. GPUs deliver much more performance on graphics computations, even though their clocks are slower, because they can exploit much more parallelism. GPU logic integrated into laptop microprocessors grew from 15 to 25% of chip area in 2010 to more than 40% by 2017…Hennessy and Patterson foresee a move from general-purpose toward domain-specific architectures that run small compute-intensive kernels of larger systems for tasks such as object recognition or speech understanding.
While many interpret the belief that we have seen the end of Moore’s law as lacking in technological optimism, that does not have to be so. Hennessy and Patterson’s 2017 Turing Award Lecture on this topic was titled, “A New Golden Age for Computer Architecture.” There’s no reason this shift in approach must result in disappointment.
The following excerpt from a version of the Turing Lecture Hennessy gave at Stanford in 2019 briefly characterizes their thoughts on what the near future of semiconductor design will look like.
I think Dave [Patterson] and I both believe that the only path forward is to go to domain-specific architectures that dramatically improve the environment and the application for that particular environment in the performance that’s achievable as well as the energy consumption. Just do a few tasks, but do them extremely well. And then, of course, combination — putting together languages which help specify applications for these particular architectures and combining it with the particular architectures.
Hennessy concludes the talk by specifically emphasizing the implications of the new domain-specific design approaches on scientific team structures, saying:
This creates a new Renaissance-like opportunity — because now unlike what’s happened for many years in the computer industry. Now people who write applications need to work with people who write compiler technology and languages; they need to work with people who design hardware. So, we’re re-verticalizing the computer industry as it was before the 1980s. And it provides an opportunity for a kind of interdisciplinary work in the industry that I find really exciting. It’s sort of like this great quote, “Everything old is new again.” It’s back to the future. And I think this will provide interesting opportunities for new researchers as well as deliver incredible advances for people who use our technology.
What did the old models look like?
Hennessy has as much of a right as anybody to be excited about the re-verticalization of hardware design and the re-introduction of the old models. This “old” era is one that Hennessy understands well; it is the era in which he came up. In the following excerpt from his oral history, Hennessy describes the integrated nature of his PhD thesis — which he called “a combination of language design and compiler technology” — on a domain-specific problem at Stony Brook:
My thesis work was on real time programming…[I worked with] a guy who was a researcher at Brookhaven National Lab [that] came along with an interesting problem. He was trying to build a device that would do bone density measurements to check for long term, low level radiation exposure among people who were working at Brookhaven. What he wanted to do was build a very finely controlled x-ray scanning device that would scan an x-ray across an arm or so and get a bone density measurement. The problem is you had to control it pretty accurately because, of course, you don’t want to increase the radiation exposure to people. And micro processors at that time were extremely primitive so the real question is could we build a…programming language that could do this kind of real time control in which you could express the real time constraints. You could then use compiler technology to ensure that they were satisfied.
After joining the Stanford department in the late 1970s, Hennessy continued to partake in projects that were structured something like the one above — such as Jim Clark’s Geometry Engine project. As Hennessy mentioned, it was normal in that era. Several historically-great computing research groups that utilized this general operating structure have already been covered on FreakTakes. Early BBN and the early CMU autonomous vehicle teams are two great examples of the dynamism of this approach at work.
While BBN was a private research firm and the CMU Robotics Institute was technically an academic group, when it came to operations and incentives, the two had more in common with each other than they did with many fellow companies or academic researchers. Both were:
Novelty-seeking
Committed to building useful prototypes and technology for users, not doing mere “paper studies”
Utilized firm-like management structures
These traits led each to great success in their respective fields. The following two subsections will briefly summarize the relevant operational strategies each used in their work that the new-era semiconductor ecosystem can learn from.
Early BBN
BBN had an exceptional talent for finding ways to generate revenue through contract research and research grants that allowed the firm to build academic ideas into real technologies. In many areas — such as real-time computing in the late 1960s — BBN was the go to group for projects that required both academic research toolkits and the kind of cutting-edge engineering which academic departments are rarely structured to pursue. J.C.R. Licklider’s Libraries of the Future project, BBN’s work as the prime systems integrator and IMP designer on the ARPAnet contract, and BBN building a time-sharing computer for the Massachusetts General Hospital in the early 1960s are just a few examples. BBN’s projects often simultaneously required bleeding-edge knowledge of computing, performed a practical service for a paying customer, and could result in technology that pushed the technical frontier forward.
BBN often did all of this with relatively small, vertically integrated teams of talented people. The firm was able to recruit many of MIT’s best researchers because of its unique model of both seeking novel technical problems and commitment to building practical technology. At the time, researchers who did “paper studies” and built basic prototypes at places like Lincoln Labs often grew disenchanted; they felt their work might not be built into industry products for a decade or more. But these disenchanted individuals still felt they would be wasted and bored if they joined a company like Honeywell. But BBN presented an exciting third option. With BBN, there were no such fears. The firm earned nicknames from MIT affiliates like “the third great university of Cambridge,” “the cognac of the research business,” and the true “middle ground between academia and the commercial world.”
With this reputation and the ability to recruit top talent that came with it, small teams at BBN could do big things. The BBN team primarily responsible for building the first ARPAnet IMPs and managing the first year of the project was only about eight people. Small is how ARPAnet team leader Frank Heart preferred it. As he saw it, that small, vertically integrated team of elite talent in the relevant areas was all BBN needed. In his oral history, he described the project’s management style, saying:
I mostly I tend to believe important things get done by small groups of people who all know all about the whole project. That is, in those days all the software people knew something about hardware, and all the hardware people programmed. It wasn't a group of unconnected people. It was a set of people who all knew a lot about the whole project. I consider that pretty important in anything very big. So I suppose if you call it a management style, that would be something I'd state. I think also that they were a very, very unusually talented group. I think things tend to get done best by small groups of very, very good people — if you can possibly manage that. You can't always manage it. So if you again want to call it a management style, it is to get the very, very best people and in small numbers, so they can all know what they're all doing.
The approach Frank Heart describes is not complex, but it’s also not how most universities handle similar projects. The more vertically integrated semiconductor design becomes, the more common it will become for BBN-model groups to be the ideal team structure for research projects. If veterans like John Hennessy are right and the computing industry is re-integrating and re-verticalizing, semiconductor research funders should ensure that groups with this uncommon structure can win funding to work on the research areas to which they are ideally suited.
CMU’s Early Autonomous Vehicle Teams
There are successful historical examples of universities operating in a very BBN-like fashion, as well. For example, much of MIT’s early history as an institute of technology dedicated to serving industry above all else demonstrates this point. In the early 1900s, the Institute placed such a heavy emphasis on contract research that, at one point, its applied chemistry laboratory was over 80% industry-funded. However, a much more recent example of this mode of operating is CMU’s 1980s autonomous vehicle research groups. CMU succeeded in maintaining a vertically integrated, applications-focused ethos in a period when most universities were taking a step back from this approach.
CMU’s autonomous vehicle vision research teams — and many other computing teams at the university — had a talent for operating in a way that could only be described as “firm-like.” Many grad students who worked on projects like the 1980s NavLab project were as much project employees as they were graduate students. They generated theses they could be sole authors on, but their work often had to be a part of a team effort on a single piece of integrated technology. Also, many staff were solely incentivized to build great technology, not rack up citations and build useful technology when they could find the spare time. In his FreakTakes interview, Chuck Thorpe recalled the following conversation he had with Raj Reddy about his incentive structure as he was being hired to manage the autonomous vehicle project:
Raj took me aside. He said, “I don't care how many papers you write. I don't care how many awards you win. That vehicle has to move down the road. If you do that, you're good. I'll defend you. I'll support you, I'll promote you.”
Aligning the incentives of key staff and organizing grad students in a way that enables the group to build the most ambitious, useful system it can makes sense. But this is also not how university’s tend to manage applied projects. Few universities succeed in doing things like creating tenured research tracks that are truly equal to traditional professorships. The best staff scientists and engineers I meet from places like MIT feel there is an obvious ceiling on how high they can rise. By getting many of these key incentive alignment, strategy, and team structure questions right, CMU built up a powerhouse research team that, in the 1980s, laid the base for the autonomous vehicle revolution.
The CMU team’s status as a sort of middle ground between academia and the commercial world proved to be a clear comparative advantage for them in the early days of DARPA’s first autonomous vehicle project, the Autonomous Land Vehicle (ALV) — detailed in a prior FreakTakes piece. At the end of the project’s first stage, DARPA had to fire the prime contractor, Martin Marietta — the “Martin” in Lockheed Martin. Martin had continually pressured DARPA to give them concrete, intermediate benchmarks to hit. When DARPA did just that, Martin found ways to hit the benchmarks without incorporating the best tech from DARPA’s basic vision researchers. The basic researchers also fell short of DARPA’s expectations. Many of DARPA’s SCVision researchers seemed more interested in collecting data from the machines’ cameras and sensors to plug into their academic projects. Oftentimes, their models would not work well when plugged into real-world machines. The academics knew this not because Martin was diligently testing each of their ideas, but because the CMU research team had pushed DARPA for modest funds to build their own vehicles. Using these vehicles, they tested and iterated upon cutting-edge vision models in a practical setting. Unlike most academic departments that did not want the massive systems integration and logistical headaches that came with this engineering-heavy task, CMU wanted to do it. DARPA was impressed by the productivity of the scrappy CMU team and continued to fund them even after the ALV project ended.
To the modern eye, the most striking early success from the CMU group might be the group’s neural net-based wheel-turning system. In my introduction to the Chuck Thorpe interview, I summarized the breakthrough:
In 1988, then-CMU grad student Dean Pomerleau successfully integrated the first neural net-based steering system into a vehicle — his ALVINN system. In 1995, Dean and fellow grad student Todd Jochem drove the successor to Dean’s ALVINN — the more complex RALPH — across the country on their “No Hands Across America” tour. The RALPH system employed neural nets but also put much more effort into model building and sensor processing. Holding Dean and Todd, the upgraded NavLab was able to autonomously drive 98.5% of the way on its successful cross-country journey.
According to Chuck Thorpe, there was something specific about Dean that enabled him to make this breakthrough with such limited compute. The trait Thorpe pointed out is one very relevant to this piece. According to Thorpe, what made Dean special was that he closely worked with the hardware developers at CMU and was one of the only people who understood how to get the most out of the group’s systolic array machine. Thorpe described Pomerleau’s extreme effectiveness in getting the most out of the Warp machine:
One of the supercomputers [DARPA] built was at Carnegie, and it was a thing called the Warp machine. The Warp machine had ten pipelined units, each of which could do ten million adds and multiplies at once.
H. T. Kung was working on systolic computing, where things just sort of chunk through the pipeline. And we said, “Here's this big box. Because we're sponsored by Strategic Computing, we'll put it on the NavLab. Can anybody figure out what to do with it?” “Well, it's a really complicated thing and really hard to process.” But Dean could figure out what to do with it. Partly because Dean is a really, really smart guy.
Partly because the inner structure of a neural net is, “Multiply, add, multiply, add.” You take these inputs, you multiply them by a weight, you add them together, you sum it up, run it through your sigmoid function. So, Dean was, as far as I know, the only person…well, that's maybe a bit of an exaggeration. Some of the speech people were able to use the Warp also, because they were doing similar kinds of things…But Dean got the full hundred megaflops of processing out of the Warp machine! And then he put it onto the NavLab and we got the whole thing to work.
It was not random that CMU was working on a systolic array computer. DARPA had contracted CMU to build the systolic array machines with computer vision as an early use case in mind. DARPA hoped that the two CMU projects would prove to be complementary. While the Warp team and the autonomous vehicle teams were not working together as one at this point, Pomerleau’s hard work ensured that they complemented each other to world-changing effect.
As Hennessy pointed out in his Turing Lecture at Stanford, Google’s now-famous TPUs with systolic array processors — optimized for machine learning applications — are a key example of the coming trend in domain-specialized hardware. Research groups that operate like BBNs ARPAnet team or CMU’s early autonomous vehicle teams seem ideally suited to help build this future.2
Everything old is new again
I am not qualified to make predictions on the future of Moore’s Law or what percentage of R&D budgets should be allocated to domain-specific semiconductor design teams. But if what people like Hennessy, Patterson, and Leiserson et al. are saying is even partially true, more research organizations set up like the best ones from the past are needed. The early operating structures of BBN and the CMU Robotics Institute, two underrated giants of the old computing community, are ideal groups to use as models.
As I understand it, Groq’s approach is rather similar to what I’ve described. And it’s phenomenal to see the progress they’ve made! But the vast majority of potential use cases for this org structure might be in market areas that are too small to raise VC rounds or for ideas considered too speculative. These are ideal areas in which to deploy CHIPS Act funding to seed BBN-like organizations and research groups. Whether it be seeding groups do practical work on the most speculative ideas coming out of academic labs or building in areas that are more important to the US than they are to VCs, BBN-model orgs have to chance to connect many pieces of the CHIPS contractor ecosystem that currently do not fit together well — just as DARPA’s contractors on the Autonomous Land Vehicle project did not fit together without CMU.
With the ramp-up in government CHIPS Act funding — endowing groups like the NSTC with up to $11 billion that has not been spent yet — now is the time to ensure groups are built up that can utilize this money as effectively as possible. One straightforward way to do this is for:
Groups like the NSTC and the DOD Microelectronics Commons to decide and make it known that they are willing to wholly fund Day 0 orgs of 5-20 talented engineers, researchers, and systems engineers organized in BBN-model project teams as contractors.
Alternative approaches that are similar in spirit but with key logistical differences are also possible. For example:
Attaching similar groups to pre-existing government contractors or universities.
Having NSTC program managers scout a domain area and assemble these teams to best fill acute needs in their portfolios.
Etc.
If any relevant parties are reading this, please reach out and I’d be happy to discuss alternative approaches and bureaucratic details. What is important is that research groups like the ones I’ve described find a way to get funding somehow.
On the university end, it would be great if institutions could quickly find ways to establish homes for research groups like this, with incentivizes and team structures that align with the task at hand. But given the difficulty of making decisions within universities that upset the natural order of things, this can often be slow and requires tough “consensus building.” So it’s maybe not worth holding our breath on that.
In the post-war period, it was common for government R&D funders to be the first — and sometimes only — major funding into new organizations of talented individuals. If they felt the team could do work that was good for the country, they took the risk. This was a common path to starting technical firms for grad students and professors. The market sizes were often modest and the teams often didn’t raise VC money. But the best of MIT, CMU, or the University of Illinois could simply set up shop as a firm and solve whatever problems the government needed them to at a fair market rate. With this recent, strong push to make things happen in the American semiconductor ecosystem, talented groups might have the chance to do something like that again.
Thanks for reading:)
Also, while doing background research for this piece and trying to make sense of the technical and management trends in different eras, I found the writing of Hassan Khan exceptionally helpful. I encourage any FreakTakes readers to check out his blog here.
If you would like to read more, check out some of the following FreakTakes pieces on related topics:
“The Third University of Cambridge”: BBN and the Development of the ARPAnet
An Interview with Chuck Thorpe on CMU: Operating an autonomous vehicle research powerhouse
One Last Announcement: Interested readers should check out this policy opportunity FAS sent over. “The Federation of American Scientists is looking for federal policy ideas to tackle critical science and technology issues. Areas of interest include R&D and Innovation, Emerging Technologies, Artificial Intelligence, Energy and Environment, Federal Capacity, Global Security, and more. Learn more and submit an idea here by July 15.”
Special thanks to former BBNer Martin Haeberli. He instructed me on how to modify this sentence to be accurate — it was inaccurate in a prior draft. If you see this, give him a follow on Twitter!
A note on Hennessy's reasoning for founding his company and the utility of BBN-model orgs:
A major reason Hennessy seems to have founded his company is that he and others felt the technology they were developing at Stanford was obviously good, but industry players seemed many years away from adopting it and building products based on it. Interestingly, this is the reason many real-time computing experts left Lincoln Labs to join BBN — to work on more practical computing projects based on their ideas. While the VC money allowed Hennessy and co to assemble a “smaller team” that was “as good pound for pound as any team that’s ever been put together,” there were plenty of sales and business model difficulties that proved to be frequent concerns for the small firm. BBN-model orgs might not have the near-term translational upside of VC-funded firms, but they can silo technical teams from existential issues like this and allow them to work on problems that are not quite market-ready or whose upside is more as a public good than one that can be substantially captured by investors.
Great article! On the deep tech VC side: completely agree with you. Software, which has dominated VC and corporate sector (Alphabet, Meta, Salesforce, etc) funding, doesn't really require as much basic research / R&D, so a lot of the "innovation ecosystem" has forgotten how to operate in the hey-day of semiconductors and early computing.
I see a lot of stuff out there that is really interesting, but not ideal to fund with private money, which is really looking for growth at a stage where things are more concrete/quantifiable, vs. speculative/R&D. SBIR and other grant funding is meant to bridge this gap, but it's a little too "applied" and meant to get companies to private funding ASAP. There isn't the time or space for this kind of integrated approach, which also has broader positive externalities.
Totally agree with you that this kind of thing is definitely where the money should go. It's just a tough sell on the political front since it doesn't yield as much immediate gratification as some factory opening up.